When scouting the web for working with SharePoint Large
Lists, you can find many articles which deal with fetching a huge number of
items from one particular list. But very little data when you want to fetch
items from a large number of sub sites. So after a little bit of poking around,
I decided to blog about some of my findings here:
The Scenario:
Here are the conditions on which I was testing:
- 1 Site Collection
- 500 Sub sites
- 1 Task List in Each sub site - > 500 Lists
- 10 items in each List -> 5000 List Items
So the total count of items I had
to query was about 5000 and according to the test conditions, the items which
would match the query were not more than 1200 at a time.
The Tools:
The tools I was using for measuring the performance were
nothing extraordinary:
1) I was
using the StopWatch
Class from the System.Diagnostics namespace. This class provides a fairly
simple and easy mechanism for recording the time a particular operation took to
execute.
This MSDN link has excellent examples on
how to use the StopWatch class for performance measuring
2) The Developer Dashboard has always been my goto
tool for performance measuring. I don’t know how I used to get by before I
started using it. It provides a wealth of information about the page load. It
can provide you with the time taken, the database calls made, the stack trace
and a whole lot of other very useful information. A good tutorial on the
Developer Dashboard can be found here.
SPSiteDataQuery:
The SPSiteDataQuery class is the heart of architecture when
you want to get data from multiple sites. This class by itself does not use any
form of caching and always returns data based on the real time queries. So even
if it takes a bit longer to fetch the data, it is guaranteed that you will get
all the current results and your users will never have to wait to see their new
items to be returned by the query.
Here is the code for doing a simple query with the
SPSiteDataQuery class:
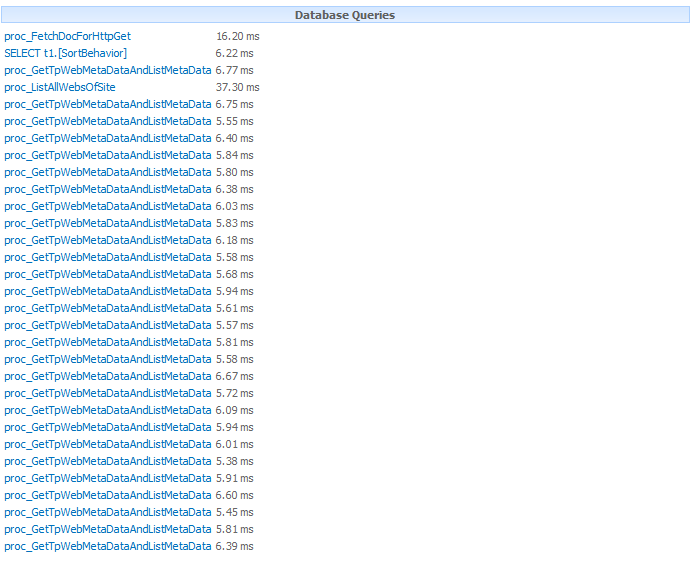
Here is a stack trace of the internal methods which are
called by the SharePoint framework when a SPSiteDataQuery is used:
So as you can see, it calls the SPRequest.CrossListQuery method which internally makes queries to
the Database to fetch the relevant results.
When querying the database the procedure proc_EnumListsWithMetadata is used. You
can have a look at this procedure in your Content DB. It queries several tables
such as the dbo.AllLists, dbo.AllWebs
etc. to fetch the relevant results.
Time taken to query
5000 items in 500 sub sites and return 1200 matching items:
650ms average on each load.
CrossListQueryInfo:
The CrossListQueryInfo class is another mechanism you can
use to fetch the List Items from multiple sites. This class internally uses the
SPSiteDataQuery class to actually fetch the items from the database and when the
items are returned, it stores them in the object cache of the Publishing
Infrastructure. When any more calls to the same data are made subsequently,
then the data is returned from the cache itself without making any more trips
to the database.
The working of the CrossListQueryInfo class
largely depends on the object cache of the Publishing Features of SharePoint
server. So you cannot use this class in SharePoint 2010 Foundation or in
sandbox solutions. Also, the default expiry time of the object cache is set to
60 seconds. So you might want to change that time depending upon your environment
requirements.
Here is the same code for using the CrossListQueryInfo
class:
Make sure to set the CrossListQueryInfo.UseCache
as true if you want to use the caching features. Another very important thing
to mention is that there are 4 overloads of the CrossListQueryCache.GetSiteData
method and only 2 of them support caching.
So only use the methods which accepts the SPSite object as one of the parameters
if you want to use caching in your code.
The Stack Trace of the CrossListQueryInfo class looks like
this:
So as you can see, the Publishing.CachedArea is queried
first to check whether the items exist in the cache. If they don’t exist, then
a call to the SPSiteDataQuery is made which fetches the values from the
database and stores it in the cache. All the next subsequent calls will find
that the items are present in the cache so no more calls with the SPSiteDataQuery
class will be made.
As a result, the very first call will take longer than a
vanilla SPSiteDataQuery call as under the hood, the CrossListQueryInfo is not
only fetching the items but also building a cache with them.
Time taken to query
5000 items in 500 sub sites and return 1200 matching items:
2000ms on first load and 30ms average on each
subsequent load until the object cache expires.
PortalSiteMapProvider:
The PortalSiteMapProvider is a class which can used to
generate the navigation on SharePoint Publishing sites. The Global navigation,
the Quick Launch and the Breadcrumb navigation can all be generated with help
of the PortalSiteMapProvider. It also provides methods to query sub sites,
lists and list items with help of caching.
The main advantage of the PSMP is that it queries the SharePoint
change log to check whether any changes have happened to the data being queried.
If yes, then only the incremental changes are fetched and thus the cache is
updated accordingly.
However, my tests showed that the
PortalSiteMapProvider.GetCachedSiteDataQuery method which is used to get items
from multiple sub sites does not maintain an incremental cache and it only
fetches the new or updated items when the object cache has expired.
So essentially when querying for items from multiple sites,
the CrossListQueryInfo and the PortalSiteMapProvider behave almost similarly.
Here is the sample code for the PortalSiteMapProvider:
The stack trace for the PortalSiteMapProvider:
You can see that it’s very similar to the
CrossListQueryInfo.
Time taken to query
5000 items and return 1200 matching items:
2000ms on first load and 30ms average on each
subsequent load until the object cache expires
So these are some of the methods you can use to query multiple List Items in multiple sites. Hope you had a good time reading through the post.
Happy SharePointing!